|
Приложение 2
Преобразования исходного ряда
Деление на тренд
Тренд, описывающий исходный ряд:
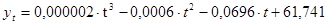
Преобразование заключается в делении фактическое значение на соответствующее ему трендовое значение.
Проверю, не представляет ли собой данный ряд процесс случайного блуждания, для чего проведу тест Дики-Фуллера.
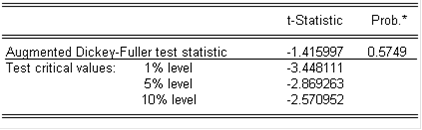
Значение статистики Дики-Фуллера превышает все приведённые в таблице критические значения. Это значит, что гипотеза о том, что ряд носит характер случайного блуждания, отвергнута быть не может.
Если построить по данному ряду модель АР(1), то будут получены результаты:
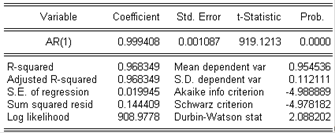
Согласно данной модели процесс описывается уравнением
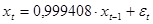
Коэффициент при 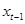 предыдущем значении ряда в модели равен 0,9994, то есть, почти единице, что свидетельствует о возможном характере случайного блуждания процесса. предыдущем значении ряда в модели равен 0,9994, то есть, почти единице, что свидетельствует о возможном характере случайного блуждания процесса.
Первый коэффициент частной корреляции выходит за пределы доверительной трубки, а последующие значения коэффициентов частной корреляции, за исключением девятого и, может быть, десятого - находятся в пределах доверительной трубки. При этом значения коэффициентов автокорреляции ряда выходят за пределы доверительной трубки и, с ростом лага, постепенно уменьшаются. Вид автокорреляционной и частной корреляционной функций для данного ряда говорит о том, что лучшей моделью для данного ряда, вероятнее всего, будет ар(1).
Всё это говорит, что гипотезу о том, что данный процесс представляет собой случайное блуждание, отклонить нельзя.
Данное преобразование нецелесообразно.
В Eviews соответствующая этому ряду серия называется «delenie».
Прирост
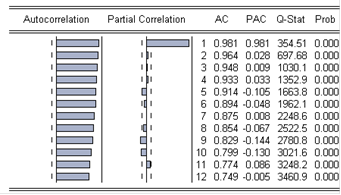
Прирост рассчитывается по формуле
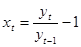 . .
Автокорреляция и частная корреляция получившегося процесса:
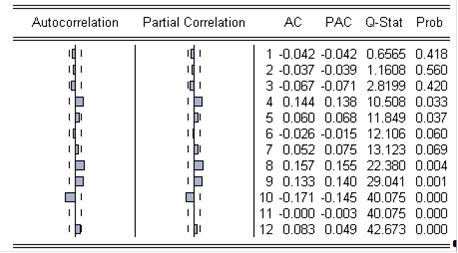
Первые три значения коэффициента корреляции и частной корреляции находятся в пределах доверительной трубки, а соответствующие им значения Q-Stat (0,6565; 1,1608; 2,8199) меньше критических (3,84146; 5,99146; 7,81473 соответственно), то есть первые три коэффициента автокорреляции ряда статистически равны 0.
Четвёртое значение Q-Stat (10,508) уже превышает критическое (9,48773), что означает: среди первых четырёх коэффициентов автокорреляции ряда хотя бы один окажется отличным от нуля (при уровне значимости 0,05). Тем не менее, по ряду «прирост» построить модель, зависящую от прошлых значений ряда будет проблематично: ведь зависимости текущего значения от предшествующих первых трёх нет, а корреляция четвёртого, восьмого, девятого и десятого порядков может оказаться наведённой.
Поэтому данное преобразование ряда не может быть выбрано для дальнейшего исследования.
В Eviews соответствующая этому ряду серия называется «prirost».
Приложение 3
Модели MA(2)ARCH
В силу построения моделей для оценки статистической значимости коэффициентов модели дисперсии ошибки может быть использован критерий Стьюдента.
Построение моделей данного типа я начала с MA(2)ARCH(9). Статистика для неё представлена в таблице:
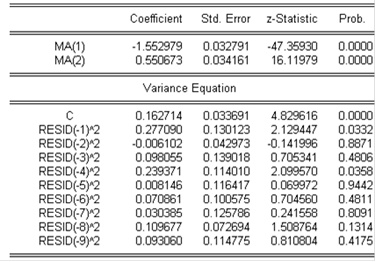
В соответствии с данной моделью процесс описывается уравнением:
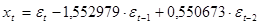
А уравнение, характеризующее дисперсию ошибки, имеет вид:
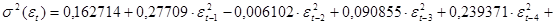
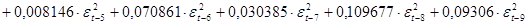
Модель дисперсии ошибки содержит отрицательный коэффициент, что недопустимо, так как может повлечь получение отрицательного значения дисперсии.
Перейти на страницу: 1 2 3 4 5 |
